
Emu Video
Emu Video generates high-quality videos from text prompts using a streamlined two-stage diffusion model approach.
Screenshots
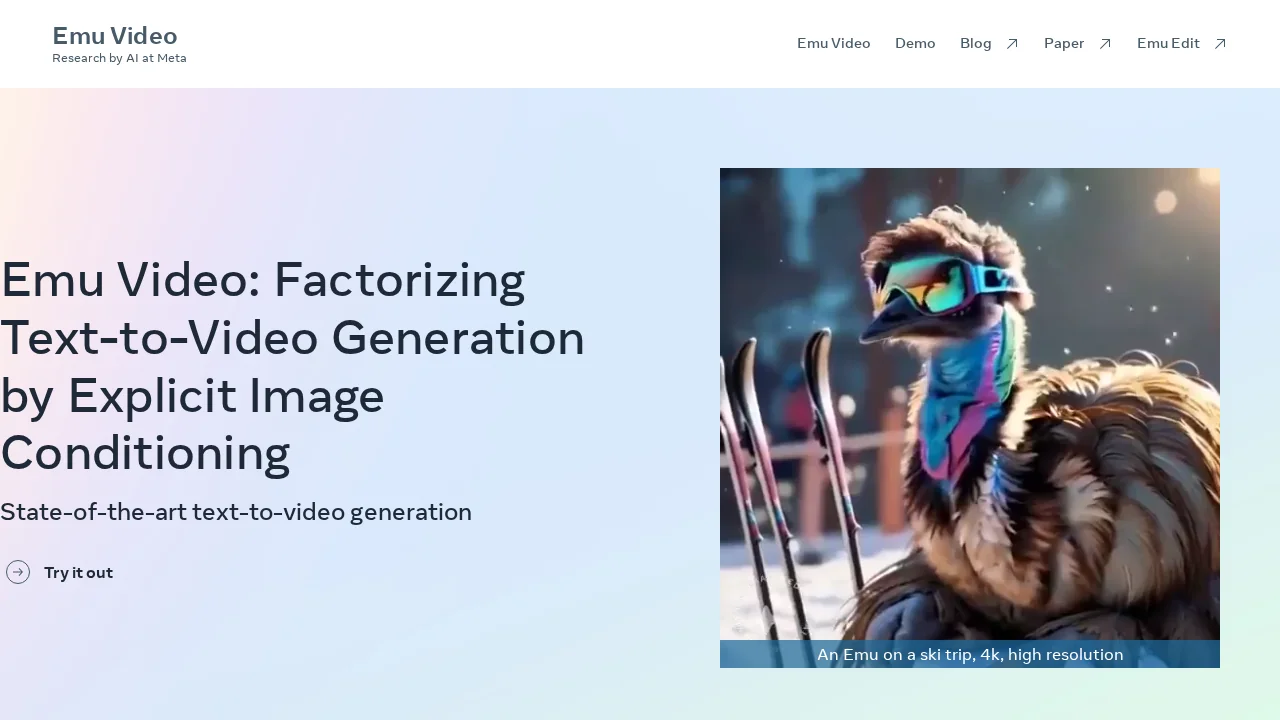
About Emu Video
Emu Video is a text-to-video generation tool that leverages explicit image conditioning and diffusion models to produce visually compelling video content. The platform uses a factorized two-step process: first generating a static image aligned with your text prompt, then animating that image into a coherent video sequence. This streamlined approach eliminates the need for complex multi-model cascades while maintaining exceptional output quality.
The tool generates videos at 512-pixel resolution, 16 frames per second, with a 4-second duration—settings optimized for both quality and computational efficiency. Human evaluators have consistently rated Emu Video's output as the most convincing in terms of visual fidelity and prompt adherence compared to competing solutions. The two-model architecture enables faster training cycles and more efficient resource utilization than traditional deep cascade methods.
Emu Video excels at translating creative text descriptions into dynamic visual sequences with impressive accuracy and consistency. Whether you're prototyping video content, exploring creative concepts, or generating reference material, the platform delivers reliable results with minimal setup. The technology represents a significant advancement in making high-quality video generation accessible and computationally practical.
Pros
Cons
Alternatives to Emu Video
FlowSub
GoFaceless
MurmurCast
Zorq AI
Scenes AI
Kinovi - AI Video Generator
MojoMake - AI Image to Video Generator