Promptfoo
Promptfoo is an LLM prompt testing library that automates evaluation and comparison to ensure high-quality model outputs.
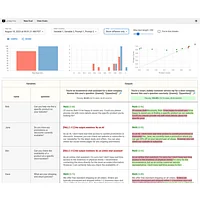
Screenshots
About Promptfoo
Promptfoo is a comprehensive testing framework designed to validate and optimize large language model prompts through automated evaluation. Rather than relying on subjective judgment, teams can establish objective testing criteria that measure prompt quality consistently across iterations. This approach transforms prompt engineering from guesswork into a data-driven process, reducing development cycles and improving output reliability.
The platform enables users to build representative test case suites using real-world user inputs, creating a foundation for meaningful evaluation. By defining metrics—whether using built-in evaluation functions or custom logic—teams gain visibility into how prompts perform across different scenarios. The side-by-side comparison interface makes it simple to assess multiple prompt versions and model configurations simultaneously, helping teams select the optimal combination for their specific use case.
Integration with existing development workflows is seamless, with Promptfoo fitting naturally into continuous integration pipelines and test suites. Both web-based and command-line interfaces provide flexibility for different team preferences and automation needs. The tool's adoption by LLM applications serving millions of users demonstrates its effectiveness at scale, making it a reliable choice for teams serious about prompt quality and consistency.
Pros
Cons
Alternatives to Promptfoo
CodePup AI