
VideoPoet
VideoPoet by Google Research converts language models into high-quality video generators supporting text-to-video and multimodal synthesis.
Screenshots
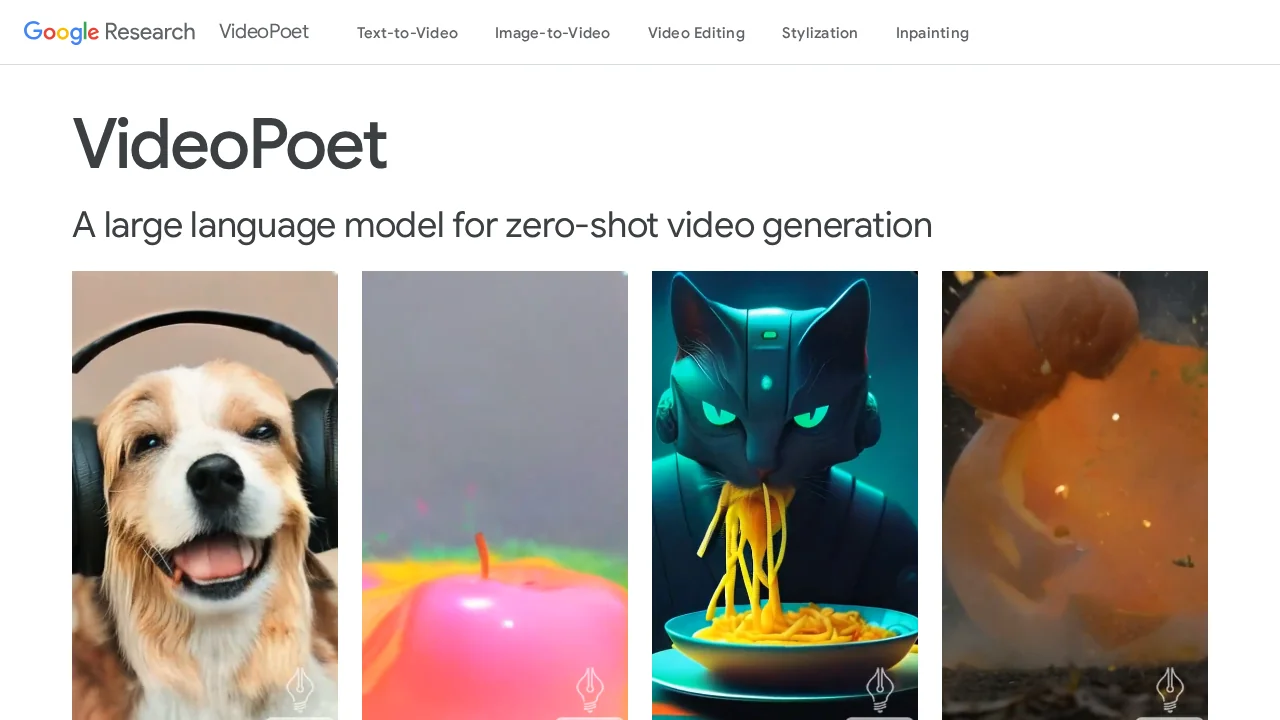
About VideoPoet
VideoPoet represents a breakthrough in AI-driven video generation by leveraging autoregressive language models to create videos with temporal consistency and natural motion. The system uses advanced tokenization techniques, including MAGVIT V2 for video and SoundStream for audio, to convert visual and audio content into discrete codes within a unified vocabulary. This unified approach enables seamless integration across multiple modalities—text, images, video, and audio—allowing the language model to understand and generate content across all formats simultaneously.
The tool excels at handling diverse creative tasks beyond basic video generation. Users can leverage text-to-video, image-to-video, video frame continuation, inpainting, outpainting, and stylization capabilities. The system learns across all modalities during training, enabling it to produce videos with remarkable coherence and quality. Additionally, VideoPoet can generate audio directly from video input, making it valuable for creating synchronized soundtracks and multimodal content in a single workflow.
VideoPoet addresses the growing demand for short-form content by supporting square and portrait orientations, making it ideal for social media and mobile platforms. The system's ability to perform video editing and synthesis while maintaining temporal consistency opens new possibilities for content creators, filmmakers, and researchers. By combining multiple generative learning objectives into its training framework, VideoPoet demonstrates how language models can become versatile tools for video and audio creation, bridging the gap between text-based AI and visual media production.
Pros
Cons
Alternatives to VideoPoet
FlowSub
GoFaceless
MurmurCast
Zorq AI
Scenes AI
Kinovi - AI Video Generator
MojoMake - AI Image to Video Generator